Oscar Van Devender did a varation of the Auzzle Puzzle and called it Tokamak:
Among the improvents Oscar mentions the following:
The eight segments were given eight different colors. The segments were rather hard to keep track of in the original version.
The magnets were placed such that the puzzle can only be solved when the top four segments are offset from the bottom ones.
While I like the shape and the looks of the colored Tokamak, and I would love to get the STL files to print one for myself (I find the original Auzzle too big for my hands), I have to admit I disagree with Oscar on both points:
Not being able to easily identify segments at rest is the whole idea! When segments are colored or marked in any way, it stops being a magnetic puzzle. Magnets start to act merely as a decoration, they are not longer vital for a solution. The puzzle is reduced to a 2x2x2 cube with a few movemenet constraints, which is still trivial for any twisty puzzle enthusiast.
Even in the non colored version, introduction of a shift between upper and lower layer does not add, but possibly (depending on an assembly process) reduces puzzle complexity even more. Here is a logical proof (you might need to refer my original Auzzle Analysis for some context):
a) Lets assume that the way Tokamak is assembled, all 8 segments happend to still be unique (i.e all numbers from 0 to 7 are being represented: 000, 001, 010 .. 111). By definition then, that puzzle has also 96 non-shifted solutions in which segments are aligned, as described in my original analysis. So the shift during assembly was pretty much a useless gesture.
b) To avoid that, we must ensure during assembly that segments are NOT unique and some encodings are not being represented. That means two or more segments must share the same binary encoding, as we still have 8 segments. That in turn means these identical segments can swap places and the puzzle would remain solved (all magnets would still attract). So total number of unique combinations is decreased by a factor of K! while the number of solutions increases by a factor of K! (where K is number of pieces sharing the same encoding).
In this post I continue the analysis of Auzzle, the magnetic puzzle invented by Ilya Osipov and attempt to come up with a simple to remember solution involving only one algorithm. See my first post for the background and initial analysis.
After practically living for three days at my friend’s house and learning more than I ever wanted to know about 3d printing, I’ve finally got myself an Auzzle to play with. The picture below shows the assembly process:
The goal
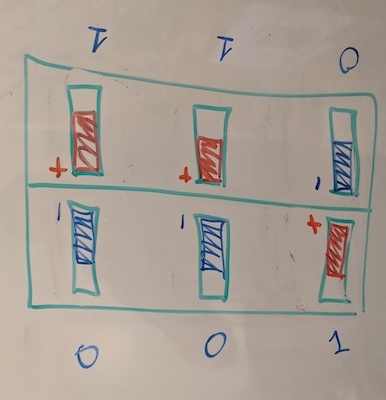
There are four pairs, or 8 pieces total in the puzzle. The goal is to move them around until we get to one of the combinations (there are multiple) where each pair is aligned vertically. In the picture below, piece #1 should be matched with #3 and #0 with #7, so swapping two pieces either on the top layer or the bottom one would solve both pairs. Obviously on a real Auzzle the pieces are not marked with colors or stickers, so our solution should not assume that, instead we need to deduce it just by looking at the magnets formations.
Notation
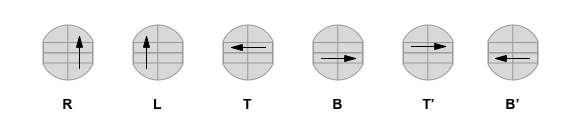
Lets try to adopt a common notation usually used in Rubik’s cube. The difference is our R and L in Auzzle always rotate by full 180 degrees, so we won’t need R’ and L’, as they are identical to R and L.
Magic algorithm
As I’ve shown in my previous post, it is always possible to get to one of the solved state within 10 moves (in fact most cases can be solved within 5-7 moves), however our goal here is different, what we would like is to come up with one basic, intuitive and easy to remember algorithm, which, when applied properly, would help us solve the puzzle. There are multiple ways to go about it, but here one of them:
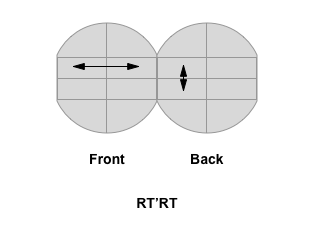
What does it do? It just swaps top left and top right pieces on the front. There is a side effect, top and bottom pieces on the right back are being swapped too. Left back is being left completely untouched. Which means, if we have some pieces already paired, keeping them in the back and performing the algorithm will not mess up their pairing, and we pretty much can ignore the side effect.
Phase 1: Getting to one pair
We don’t really need any algorithm for this. We will just rotate the top (T) and will likely get at least one pair matched, if we don’t, after making a full circle, we rotate right side (R) and then rotate (T) again, we WILL eventually get some pairs matched.
If we are really lucky and we got all 4 matched, the puzzle is solved. If we got two pairs matched, we skip to phase 3. Otherwise we need to get us a second pair first.
Phase 2: Getting the second pair
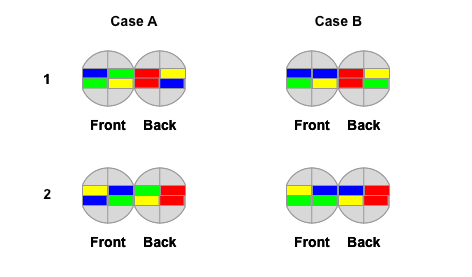
Remember how we said our magic algorithm doesn’t really mess up anything in the back? So we can put our matched pair in the back left or right quadrant and try performing the algorithm to swap pieces at the front, until we get our second pair matched. The problem is, it won’t always work :) In order to explain why, I will use 4 different colors, as before, to represent 4 different matching pairs. Auzzle with one matched pair generally falls within one of the two cases above:
Note: If you look closely, A1 and A2 is actually the same case, just rotated 90 degrees. Similarly B2 is just a rotated B1.
Case A: This is the easy one, for each unsolved pair, one piece is located on the top and one on the bottom. It doesn’t matter where we put our first matched (red) pair, as long as it is on the back it will remain untouched. But the moment we perform our magic algorithm, second pair (either green or blue) is going to get matched.
Case B: Here matching pieces are colocated on the same top or bottom planes. Which means performing the magic algorithm will not result in any new pairs being created.
How can we know whether we are in case A or B? That is actually easy, we can rotate the top layer one click right (T’) or left (T). If another pair (our green or blue ones) is getting matched, we are in case A, otherwise we are in case B.
Phase 3: Last two pairs
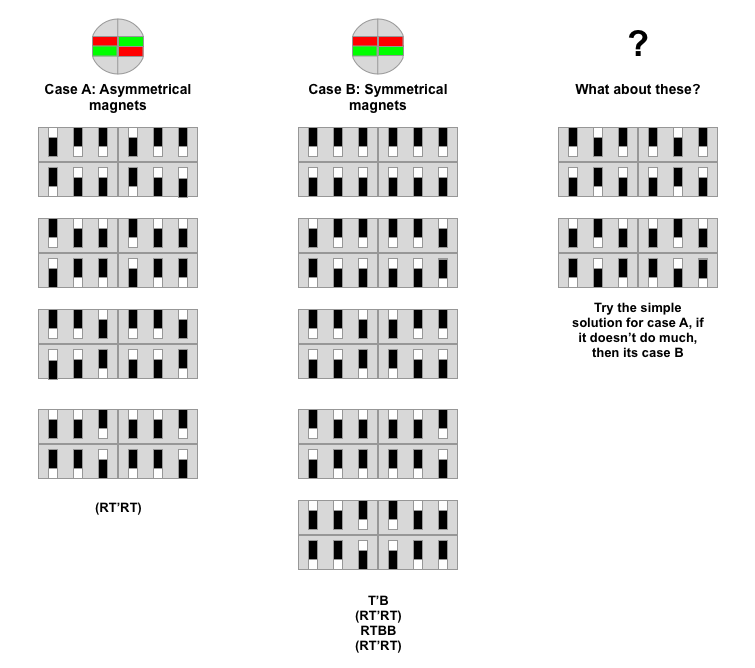
Ok, we got 2 pairs matched, just bring them both to the back, and lets work with the unmatched pieces at the front. There are two ways how 2 pairs can be potentially unmatched (see diagram below). On a real Auzzle we obviously won’t see green and red segment colors like in the diagram below, but we can see the magnets interaction and infer the case we are dealing with:
Case A: The easiest one is when we notice an asymmetrical configuration of the magents. The pieces are crossed! We can just perform our magic algorithm to swap to top left and right pieces and the puzzle is solved!
Case B: This one is a bit trickier. The left and the right side are clearly symmetrical. That tells us the pieces are not crossed. Swapping two top ones will not help us much, we will end up exactly where we started. We need to break the “parity” of the puzzle and get to the Case A we love so much.
There are also two magnet configuration which don’t tell us whether we are in A or B. How can we know? Lets try to rotate top layer (T’). If the this is case A (crossed), we will immediately see the pair matched, we are in Case A, rotate the top layer back (T) and perform the magic algorithm. Otherwise we are in Case B.
In fact, if you would rather not think at all about Case A or Case B and dont' care about few extra twists, you can always try to perform the algorithm for A, and if the puzzle is not solved continue to B (i.e
I am sure there are more effective ways to solve the puzzle with less (5-7) moves, even just memorizing and using all the mirror variations of our magic algorithm above would make a huge difference and save tons of unnecessary moves. Phase 2 should be improved too. It’s a start, stay tuned for updates.
Disclaimer: I do not own one. All the work below is my attempt to analyze it after having the pleasure to see and play with a prototype for a few minutes.
Theory
At first glance the puzzle looks quite overwhelming. It consists of 24 magnets, arranged in pairs, and depending on the polarity of the magnets in the pair, they are either pulled towards the middle, or pushed towards the outer edges. The wooden or plastic pieces holding these magnets can be rotated in multiple directions, constantly changing the matching between the magnets. The puzzle is solved only when all 12 pairs of magnets are pulled towards the middle.
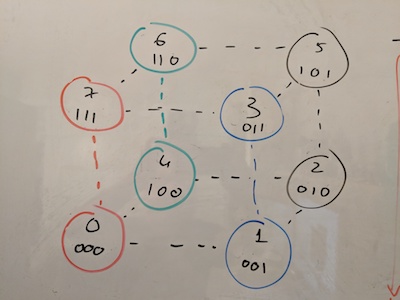
After further inspection, however, it becomes clear that the things are not as bad as they seem. There are actually only 8 unique solid wooden or plastic pieces, each one containing 3 magnets. In other words, only 4 pairs of 2 pieces each. The placement of the magnets within each piece is unique, we can actually represent it as a binary encoding, 1 if the magnets ‘+’ is pointing towards the center, and 0 if ‘+’ points towards the outer edge. Unsurprisingly, 3 bits is the exact number required to encode 8 unique pieces: #0=000, #1=001, #2=010, #3=011, #4=100, #5=101, #6=110, #7=111.
Therefore, each piece has only one and only one matching piece resulting in all 3 pairs of magnets pulling towards the middle.
If we keep thinking in binary, in order for a pair of pieces to be each others matching counterparts, the following condition has to be true:
A xor reversed(B) == 7
It is easy to overlook the "reversed" part, but it is important! We encode every piece in the same way, 1 always means '+' pole is oriented towards the center. Pieces will change their orientation, sometimes they will face up and sometimes down, but when faced each other, we can't operate directly on their encodings, we must remember the top one is upside down (i.e piece 001 (1) will atract magnets in the 110 (6) formation, however the actual encoding of that opposing top piece is 011 (3))
In other words, in order to solve the puzzle, piece #0 must be placed against piece #7, #4 against #6, #1 against #3 and #2 against #5.
Total combinations
Total amount of permutations for 8 unique pieces is 8! = 40,320
We also need to multiply it by 2 to account for two possible states of the outer shell in relation to the internal mechanism.
However if we take any state of the puzzle, whether we rotate it by 180 degrees along X or rotate it in any of the 4 orentations along axis Y, it is still the same state, we don’t want to count each state 8 times, so we divide by 8 respectively.
Total number of combinations: 8! x 2 / 8 = 10,080
What about possible solutions?
The picture above shows only one possible solution of the puzzle. However it immediately becomes clear that the puzzle has many possible solutions: a) within each pair, the two pieces can swap places; b) the position of the pairs relative to one another can change and the puzzle would still remain solved.
Permitations to place 2 matching pieces within a pair: 2
We have 4 of these pairs, so total number of permutations is 2^4
Number of ways to place pairs in relation to one another: 4!
Similarly to how we did it before, we multiple by 2 to account for 2 possible states of the outer edge.
And, again, divide by 8 to account for rotation of the whole construction and avoid counting each state as 8 different ones.
Total number of solutions: 4! x 2^4 x 2 / 8 = 96
Observation #1: It is possible to screw up the assembly of the puzzle and insert magnets in a way that will result in pieces with identical encodings existing within the same puzzle. The number of possible solved combinations will increase, the total number of combinations will decrease. Ouch!
Observation #2: In a proper puzzle that actually has 8 uniquely encoded pieces, it is IMPOSSIBLE to get to a state where all the 12 pairs are pushed towards the outer edges. Piece #0 (000) will only push all 3 magnets when paired with another #0, and since there should be only one #0 piece in the puzzle that should never happen. This is true for any encoding that is a ‘palyndrome’ in a 3bit range (i.e #0, #2, #5, #7) (see 4bit variation for a way to possibly do it with 4 bits)
Practice
In order to validate my theory and also calculate the God’s Number (maximum number of moves God has to perform to get to a solved state), I’ve written a simple simulator that tries to scan all possible states by doing it in reverse, starting with a solved state and traversing the tree of all the possible states. The code can be found in sim.py. It starts at the at the initial solved state shown in the picture above, then performs a BFS’ish scan of the whole space by performing all possible operations. For every state, to avoid double counting rotations (remember the division by 8), it rotates the whole puzzle to a canonical state where piece #0 is inside the lower left quadrant.
1
2
3
4
5
6
7
8
9
10
11
12
13
python sim.py
Total combinations: 10080, Solutions: 96, Max path to solution: 10
Number of paths oflength0: 96
Number of paths oflength1: 192
Number of paths oflength2: 288
Number of paths oflength3: 480
Number of paths oflength4: 768
Number of paths oflength5: 1824
Number of paths oflength6: 2688
Number of paths oflength7: 3264
Number of paths oflength8: 192
Number of paths oflength9: 192
Number of paths oflength10: 96
I am sure it can be done much more efficiently, but that was a quick and dirty exercise and it proves my theoretical calulations (the numbers match!). It also reveals the God’s Number for Auzzle, that number is 10! 10 moves is all it takes to get from the worst position to one of the 96 solved states.
Actually solving it
Given the total number of combinations and the total number of solutions, it is actually pretty easy to get to one of the solved states just by fidgeting with the puzzle enough time.
If we mark the matching pieces with 4 different colors like in the picture above, the puzzle is trivial to solve systematically. In fact, we can think of it as a subset of a 2x2x2 cube where one axis rotates only by 180 and another axis doesn’t rotate at all.
However, individual pieces are not marked and the only thing that can be observed externally by looking at the magnets is the result of the interaction between two adjustent pieces (representing A xor reversed(B)). This makes it much more challenging.
Update: I’ve 3d printed an Auzzle and played with it a bit, please see my next post on actually solving it.
Variations
4bit
In this variant, we have more possible encodings (16) than needed to represent 8 unique pieces, however that allows us to skip encodings that require duplicated pieces:
a) Avoid encodings #0, #6, #9 and #15 (#0 will only fully push away another #0, etc)
b) Avoid encodings #5, #3, #10, #12 (#5 will only fully pull another #5, etc)
That leaves with 8 encodings that do not have any of the issues above, each one of them has a proper counterpart for pulling all 4 of its magnets and and another one of pushing all 4. These encodings are: #1, #2, #4, #7, #8, #11, #13 and #14. And the actual matching pairs for both solutions are as follows:
It would be logical to assume the total amount of combination will not change (the amount of pieces did not change, it is still 8). The amount of solution states should probably double to 192 (96 inside and 96 outside), and the God’s number should probably decrease by 1 as well (worst case should probably be only 9 moves away from one of the solved states). To test it, I’ve duplicated the simulation and modified it to work with the 4bit encodings above, the code can be found sim-4bit.py
Results:
1
2
3
4
5
6
7
8
9
10
11
12
python sim-4bits.py
Total combinations: 10080, Solutions: 192, Max path to solution: 9
In the previous post, we’ve learned what is symbolication process and why it is needed. In this post we will dive deeper and learn how to make sure a dSYM file is generated and see how we can manually use it to symbolicate crash reports.
How do I make sure dSYM is actually being generated?
XCode has several settings that may affect dSYM generation, let’s review them one by one.
First of all, let’s make sure that debug information is being generated:
Let’s instruct XCode to put the debug symbols in a separate dSYM file:
By default that option is only selected for release builds, but not for debug builds. In most cases it is enough, as most commonly debug builds are only used by the developer while debugging their own application while being attached to XCode. However when trying out symbolication or when there is a chance a debug build is going to end up on a device of a colleague who is going to test it, we may still opt to have the dSYM file to be able to analyze the crashes.
And last, but not the least important:
This option is not important for the symbolication process itself, but it is important to check it, as it instructs XCode to strip the debug symbols from the binary file itself, the file we are going to distribute to App Store. It both affects the size of the distributed application, but more importantly, leaving debug information in the application makes our competitors’ life much easier.
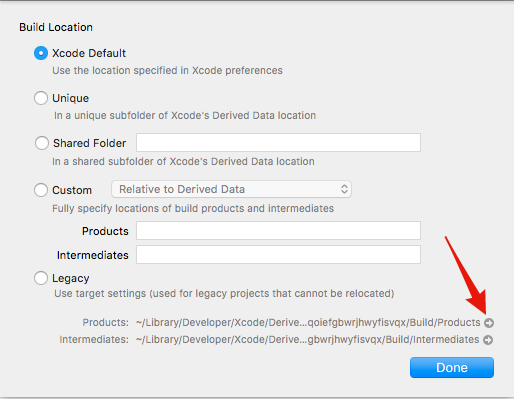
With all these options checked, our next build should produce a dSYM file (or rather a series of dSYM files, one for our main application and one for each framework we build as part of our application). The files are located in the products folder. Apple made it quite tricky to find it, one common method is to look at the build logs and copy the path from there. There is an alternative way through XCode:
Go to File->Project settings
Click on Advanced
Clicking on that small arrow will reveal the product folder in Finder
Note: XCode 8.2 was used at the time of writing the post, the options may differ in other XCode versions.
What can I do with a crash report and a dSYM file?
Let’s say we have that raw crash report with addresses and a dSYM file that we know is the matching one. What can we do with it? The address and the dSYM file should be enough to extract debug information about that address, but there is still one element missing. We need to know the exact address that image was loaded at for that specific crash. The reason for this is operating system randomizes the offset at which programs are being loaded every time they are ran. The technique is usually called ASLR (Address Space Layout Randomization) and it is mostly done for security reasons, as it prevents exploits that rely on a specific layout of the program at runtime.
This is where the list of all the loaded images comes into play. If you are dealing with raw crash reports generated by XCode, it can be found in the “Binary images” section of the text file.
Now that we know that at that particular run our application has been loaded at 0x10007C000, we can use the atos tool that comes with XCode to try to extract more info:
getElementFromArray (in MyApplication.app.dSYM) (AppDelegate.m:22)
That seems to be working. But that is a lot of tedious work if we do it manually. If we want to get nice human readable snapshot of the callstack, then for each address, we have to:
Find the image that address is corresponding to in that particular run of the application (remember the ASLR?).
Get the start address for that image
Locate the dSYM file for that specific image. (Where do we get dSYM files for all the system images? *)
Use atos tool to translate the address into a human readable location.
When you deal with XCode raw crash reports, there is a perl script that’s shipped in one of the frameworks that can partially automate this flow. In XCode 8.2 it can be found in: /Applications/Xcode.app/Contents/SharedFrameworks/DVTFoundation.framework/Versions/A/Resources/symbolicatecrash but it may vary from version to version.
In fact, locating dSYM files for system frameworks is major pain point for most developers. These dSYM files are usually located in ~/Library/Developer/Xcode/iOS\ DeviceSupport/ folder. However this folder is populated by XCode and only contains symbols for iOS versions and architectures that were attached to that particular XCode. (i.e if you’ve never debugged an armv7 device running iOS 8.2 to your Mac, you will not have iOS 8.2 armv7 symbols on this machine.) Good news is starting with iOS 10, Apple dropped the support for all old armv7 devices, and both arm64 and armv7s support files are shipped with iOS regardless of the arch of the device itself. So it is enough now to attach any device with iOS 10.2 to XCode to have support files both for armv7s and arm64 flavors. It is still practically impossible to “collect them all”, however, especially when Apple sometimes releases iOS beta builds daily.
With this script in hand we know how to completely symbolicate one single crash. And that is assuming we got the crash report itself, all the dSYM files, all the tools and a lot of patience. In the real world however, this approach becomes impractical really quickly, as our app is deployed on thousands (hopefully millions!) of devices, all having different iOS versions and architectures. And in order to have a complete solution we have to:
Have system frameworks dSYM files for all available iOS versions and architectures out there
Be able to match and combine similar crashes, even if they have somewhat different stack traces, but share identical root cause
Automatically catalogue dSYM files for each application and framework build we produce
Detect, register and process every crash from every user and device
Analyze app crash statistics and trends per device, iOS version, App version, etc.
That is exactly where 3rd party crash reporting services come into the picture. Crash reporting can do that and much more, leaving us time to focus on building the app itself instead of spending precious time on building infrastructure and toolchains for debugging and analysis. Crash reporting services differ when it comes to quality of the stack trace reports, as well additional contextual information they provide about the crashes. Bugsee crash reporting has recently been ranked the highest among all iOS crash reporting services when it comes to accuracy and the amount of details in the report. Bugsee doesn’t stop there, however, it also presents video of user actions, console logs and network traffic that preceded the crash.
In the next post of the series, we will be diving deeper into advanced topics of symbolication such as Bitcode.
Many developers use Bugsee for its great crash reporting capabilities. In fact, Bugsee crash reporting has recently been ranked the highest among all iOS crash reporting services when it comes to accuracy and the amount of details in the report. Bugsee doesn’t stop there, however, it also presents video of user actions, console logs and network traffic that preceded the crash.
In the following series of posts we are actually going to focus on the crash log itself, explain the magic behind it and show how to properly set it up.
First post in the series is an introductory one.
What is symbolication?
In order to answer that question we must briefly touch on the build process itself. Regardless of the language our project is written in (be that Objective C, Swift or any other), the build process translates our human readable code into machine binary code. Consider the following buggy code (can you spot the bug?).
1
2
3
4
5
6
7
8
9
10
11
12
13
void initialize() {
array = @[@"one", @"two", @"three"];
}
NSNumber* getElementFromArray(int index) {
returnarray[index];
}
void printAllElements() {
for (int i = 0; i <= 3; i++) {
NSLog(@"%@", getElementFromArray(i));
}
}
After build it will eventually become this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
0x100117dec: stp x29, x30, [sp, #-16]! ; <--- Start of the initialize() method
<...skipped...>
0x100117e9c: ldp x29, x30, [sp], #16
0x100117ea0: ret
0x100117ea4: bl0x10022d83c
0x100117ea8: stp x29, x30, [sp, #-16]! ; <--- Start of the printAllElements() method
0x100117eac: mov x29, sp
0x100117eb0: subsp, sp, #32
0x100117eb4: stur wzr, [x29, #-4]
0x100117eb8: ldur w8, [x29, #-4]
0x100117ebc: cmp w8, #3
0x100117ec0: b.gt 0x100117f08
0x100117ec4: ldur w0, [x29, #-4]
0x100117ec8: bl0x100117f14; <---- this is where it calls getElementFromArray()
0x100117f44: bl0x10022d608; <--- Here we send message to NSArray to retrive that element
0x100117f48: movsp, x29
0x100117f4c: ldp x29, x30, [sp], #16
0x100117f50: ret
As you can see from this example, the build process got rid of all the symbols (variable and method names), it also doesn’t know anymore anything about the layout of our code, the amount if spaces we put to separate the functions, all that information is lost. So now when crash occurs (and it will occur, after all we access elements beyond the bounds of that array), if we don’t have symbolication properly set up, this is the only crash information we will end up with:
This is pretty raw, and not very useful. We know it failed in some method inside the CoreFoundation system method, which was in turn called from some method in libobjc.A.dylib, which was in turn called from another method in CoreFoundation, which in turn was called from our application (finally!). But what is 0x100117f48? Where exactly is it? What file, function or line number is it? That is exactly where symbolication comes in.
Symbolication is the process of translating the return addresses back into human readable method/filename and line numbers.
Successful symbolication will result in the following report instead:
1
2
3
4
5
6
NSRangeException: *** -[__NSArrayI objectAtIndex:]: index 3 beyondbounds[0 .. 2]
Now it’s pretty obvious that crash was caused by some improper array access in line 22 of MyFile.m, which happens to be within getElementsArray method. And if we need more context, we can easily see this one was called by printAllElements at line 27 of the same file.
What is a dSYM file?
Luckily for us, XCode can be instructed to keep a lot of the data that is being lost during the build process. It can put it inside the application itself, but that is not a good idea. We do not want to ship our application with all these extra debugging information, it will make it very easy for our competitors and hackers to reverse engineer the app. We would like to have it generated, but kept out of the AppStore. That’s exactly what dSYM file is all about. During the build process, XCode strips all the debug information from the main executable file, and puts it inside a special file called dSYM. This helps to keep our executable small and easier to distribute to happy customers.
If our application is using frameworks, the product folder will have a separate dSYM file generated for each framework built. Eventually all of them are needed if we want to cover our bases and be able to symbolicate a crash in every possible location in our app.
Needless to say, a dSYM file generated while building a specific version of the application can only be used to symbolicate crashes from that specific version only. dSYM files are identified by a Unique ID (UUID), which changes every time we modify and rebuild our code, and that ID is what is used to match a symbol file to a specific crash. A dSYM may be associated with more than one UUID, as it may contain debug information for more than one architecture.
The UUID of a dSYM can be easily retrieved using the dwarfdump command:
The dSYM above has debug information for both arm7 and arm64 flavors of our application, each flavor has its own UUID.
These dSYM files can and should be manually stored for future symbolication of the crashes in the production build. Alternatively they can be uploaded to a crash reporting service like Bugsee, where they will be put in a vault and will get eventually used for processing a crash for that specific build. Typically, a special build phase is added to the build process that is responsible for uploading dSYM files to the vault.
What happens during iOS crash?
During crash the following information is being collected on the device:
Crash/exception type and an exception specific message (if and when available)
Stack trace for each thread (in raw form, the list of these unreadable return addresses that we saw before)
List of all images (user and system frameworks and extensions loaded by the application. Each one has a unique UUID to help match it to the right dSYM file)
Other information about the specific build, device, time of the crash, etc. These are less relevant to the symbolication process, but important nevertheless.
This information is sent for processing to the crash reporting service, where it will be matched with proper dSYM files that were already uploaded at build time, or will be uploaded manually at a later time. The symbolication process happens on the server and produces a nice, human readable crash report that can either be viewed through a web dashboard or downloaded as a file. The report will typically include the items listed above (basic info, crash/exception details and symbolicated stack trace if all the stars are aligned and all symbol files were properly uploaded and processed.
That is what a typical crash reporting service provides. Bugsee provides much more than that, to name a few, with Bugsee, these reports also include an interactive player that can play in a synchronized manner the following:
Video of the screen and user interactions that preceded the crash
Network traffic, with complete request and response headers and body
System and application traces (disk space, cpu loads, top view and window names, etc.)
Your custom traces
Console logs
This gives much more context that is of tremendous help when trying to debug an evasive issue that is only happening for customers in the field.
In the next post of the series, we are diving deeper into symbolication process itself, and show how to manually symbolicate an address or a full Apple crash report.
Applications today are rarely being built without 3rd party libraries and SDKs. There are libraries for integrating remote backends into your app. Libraries for effective image caching and loading. Libraries for gathering analytics and libraries for pushing messages. Libraries that help your users report issues, help you debug and analyze crashes. (Yes, that last one is Bugsee)
It is also a common practice for developers to maintain more than flavor of the application during active development. A debug version of the application may require a new version of the backend server which also might be under development still, it might send analytics data to a different service or it may need to include a helper library that is not necessary in the release version.
This following tutorial describes several options for maintaining different build configurations.
We are using Bugsee SDK as an example in this tutorial. At the same time, we do want to point out, that Bugsee SDK is extremely lightweight and doesn’t impact your user’s experience. Bugsee also passes all Apple Appstore requirements. A lot of Bugsee’s customers have seen the benefits of shipping the library in their App Store builds, it provides them with video-enabled crash reporting and in-app bug reporting.
Debug vs. Release
This one is the default most common setup you get when you create your application with xCode. With preprocessor macros it is easy to differentiate at compile time between a Debug and a Release build. Thus, it is easy to launch (or not launch) a library in any particular configuration. Lets launch Bugsee only in Debug build.
So now you don’t import and don’t run it, but the framework is still getting packaged into your application. If you use CocoaPods for you library management, there is a solution, starting with v0.34, CocoaPods honors build configurations. All you have to do is put the following in your Podfile:
1
pod 'Bugsee', :configurations => ['Debug']
Unfortunately, if you manually copy libraries into your project, you are out of luck.
Debug vs. Release (+TestFlight)
In this configuration you still manage and maintain two build flavors (Debug and Release). The Release build is first distributed to QA and Beta testers through Apple TestFlight and only when ready you promote it to App Store. The beauty of this approach is that it is the same build(same binary!). Thus, you can be sure there are no differences between what was tested and what was released. This means, however, that Bugsee SDK must be part of that Release build and you just want to disable it when it is being installed from App Store.
Fortunately, it is easy to differentiate between App Store and Testflight installations in run-time and initialize Bugsee only when appropriate:
if ([[[[NSBundle mainBundle] appStoreReceiptURL] lastPathComponent] isEqualToString:@"sandboxReceipt"]) {
// We are in TestFlight, enable Bugsee!
[Bugsee launchWithToken:@"your app token"];
}
returnYES;
}
Debug vs. Release vs. Beta
In this setup you create and maintain three build flavors. Distribution method of the Beta flavor is not important, it can be done either through Ad-hoc distribution (see our tutorial on building in house Ad-hoc distribution using S3) or through TestFlight. In this setup you are back to detecting the configuration at compile. Adding an additional configuration, however, is a multi step process:
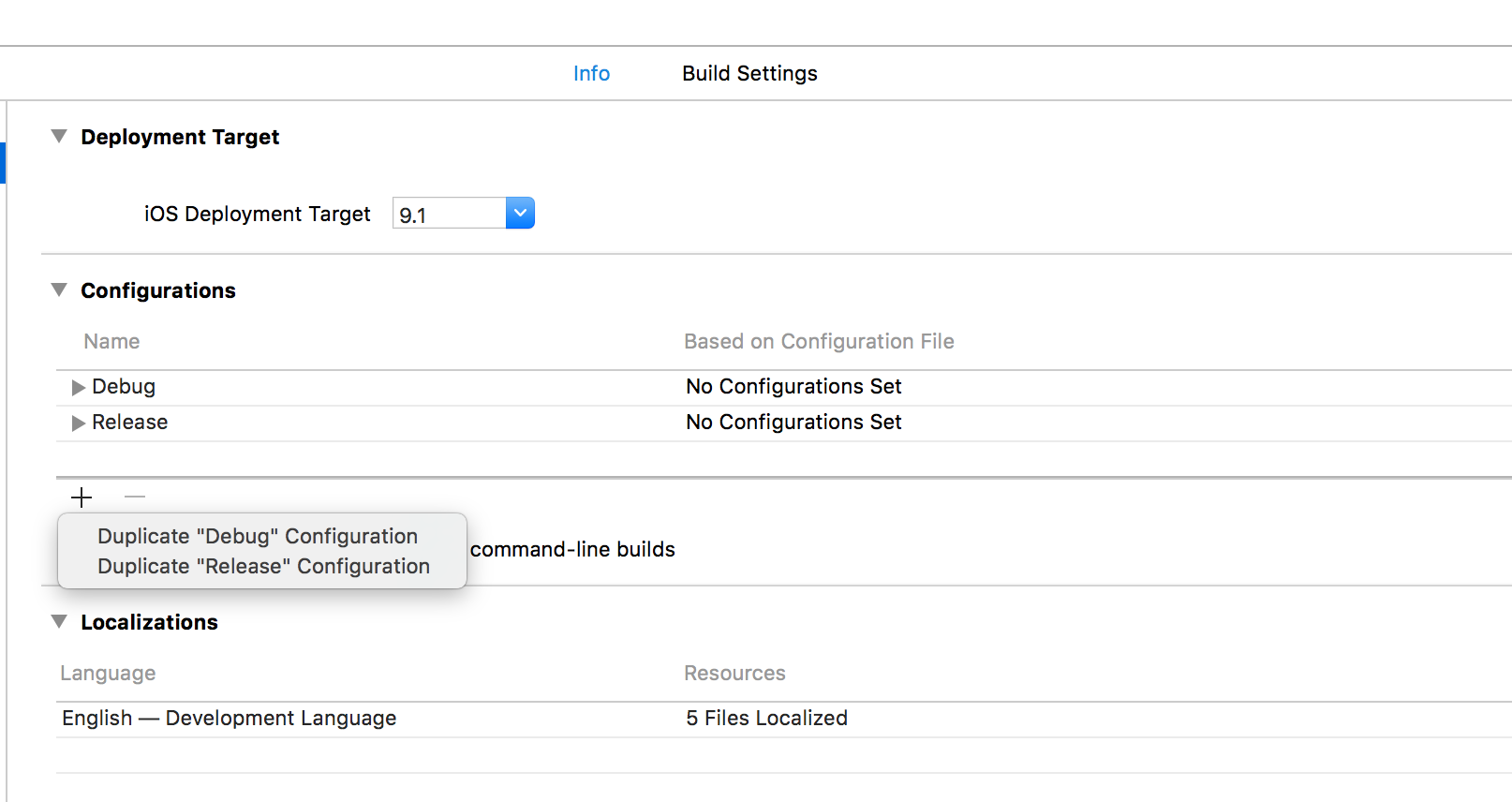
Go to your project Info, and under Configurations, create a new one by duplicating the Release one.
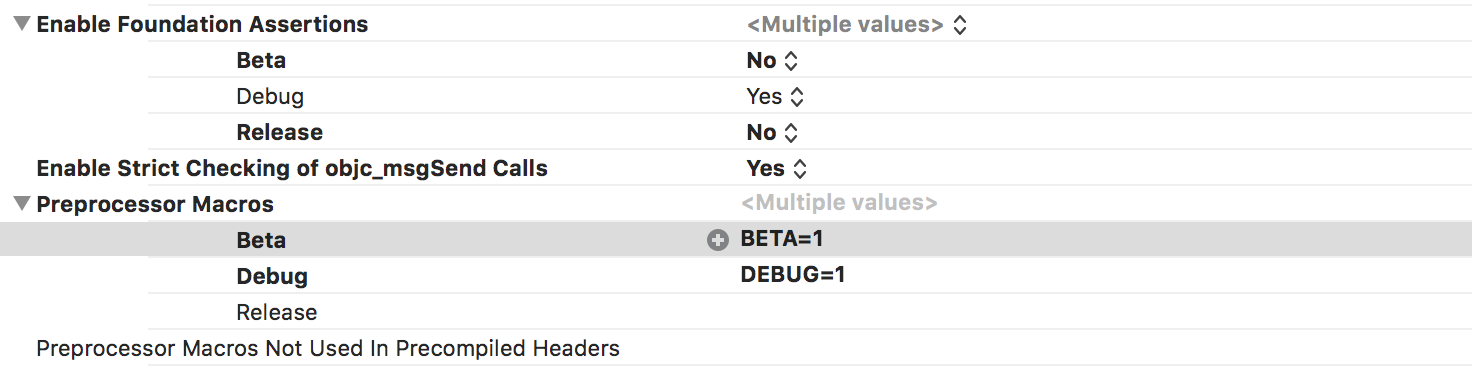
Go to Build Settings and in Preprocessor Macros and add BETA=1 to that new Beta configuration (note that this is actually the place DEBUG=1 is being set for that Debug build).
Voila! You can now detect Release versus Beta build at compilation time. Other than the BETA flag, the builds are identical.
Let’s use that CocoaPods trick to install the library only in Debug and Beta builds:
1
pod 'Bugsee', :configurations => ['Debug', 'Beta']
The only thing left to do is to build the Beta configuration.
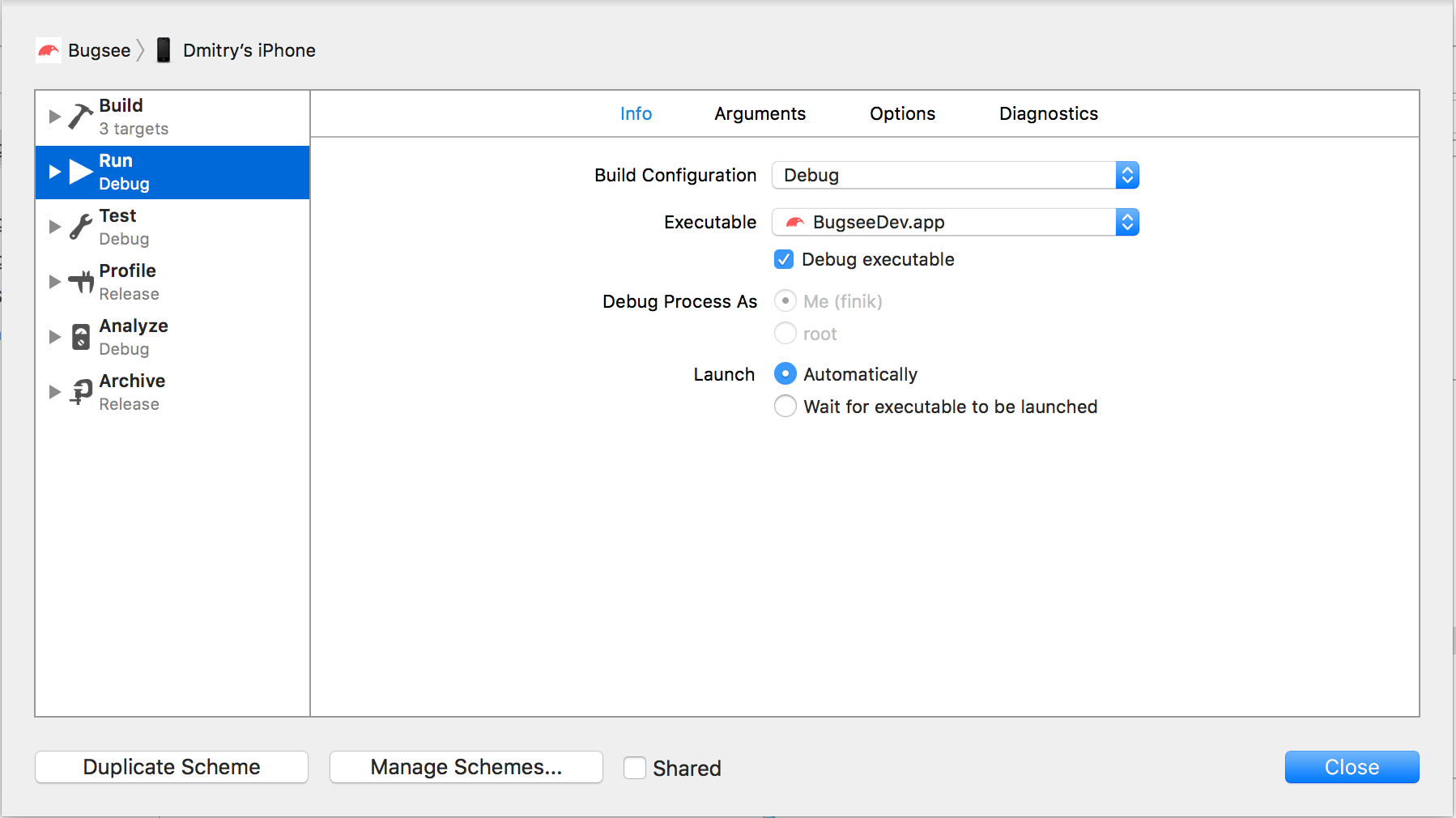
First of all, go to Product->Schemes->Edit Scheme and click on Duplicate Scheme button. Name it properly (if your original scheme was called MyApp, call the new one MyApp Beta).
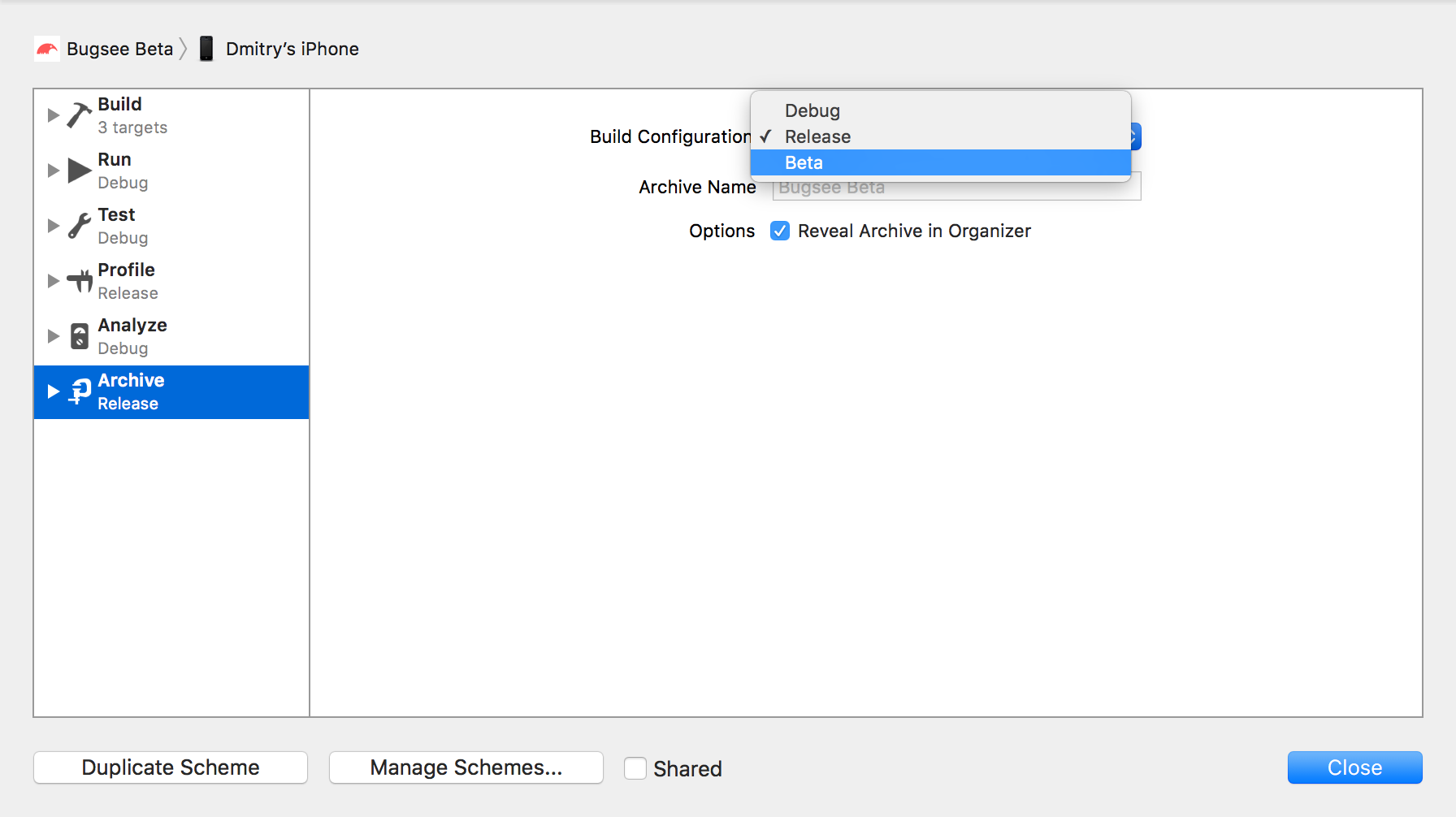
Edit the new scheme, and change the configuration of the Archive step to use Beta configuration.
That’s it. Now you have two schemes, one for Appstore and one for Beta releases. As long as you are developing and using Build & Run, they are identical, and it doesn’t matter which one you are using. It matters though when you do Archive, depending whether you want to produce and IPA for App Store or Ad-Hoc, remember to switch to the right one.
Every iOS developer at some point in their life is challenged with a task to distribute their awesome app to a group of loyal beta testers. Apple does not make it easy. The reasons for this are clear. We all care about security and greatly appreciate the fact that iOS platform is much more secure than its main competitor, but it is still a problem that needs to be solved. There are services out there that try to automate the ad-hoc distribution process, but sometimes it is not desirable or even possible to use them. Thus, there is a need to bake an in-house distribution system.
To make the ad-hoc distribution work, one must:
Upload the IPA file to a place where it can be downloaded
Generate a special plist xml file, referring to the IPA above. This file must be accessible over https!
Generate an html file with a special Download link, pointing to the plist file above. This is the page users will see
Throughout this tutorial, we are going to use an application called Dishero as an example. We will host it directly on S3, without spinning up machines or configuring http servers. The result will look similar to this:
We will produce a nice webpage, hosted on S3 that will provide details and a one-click install for our application.
Prerequisites
Create an Ad-hoc distribution profile
First of all you will need to create a distribution profiles in iTunes Connect.
Ad-Hoc distribution limits the the ability to install your application only on specific devices that have to be pre-registered. Instruct your beta users to visit http://whatsmyudid.com/ and to follow the instructions there to obtain UDID (Unique Device ID) for their device and send it to you.
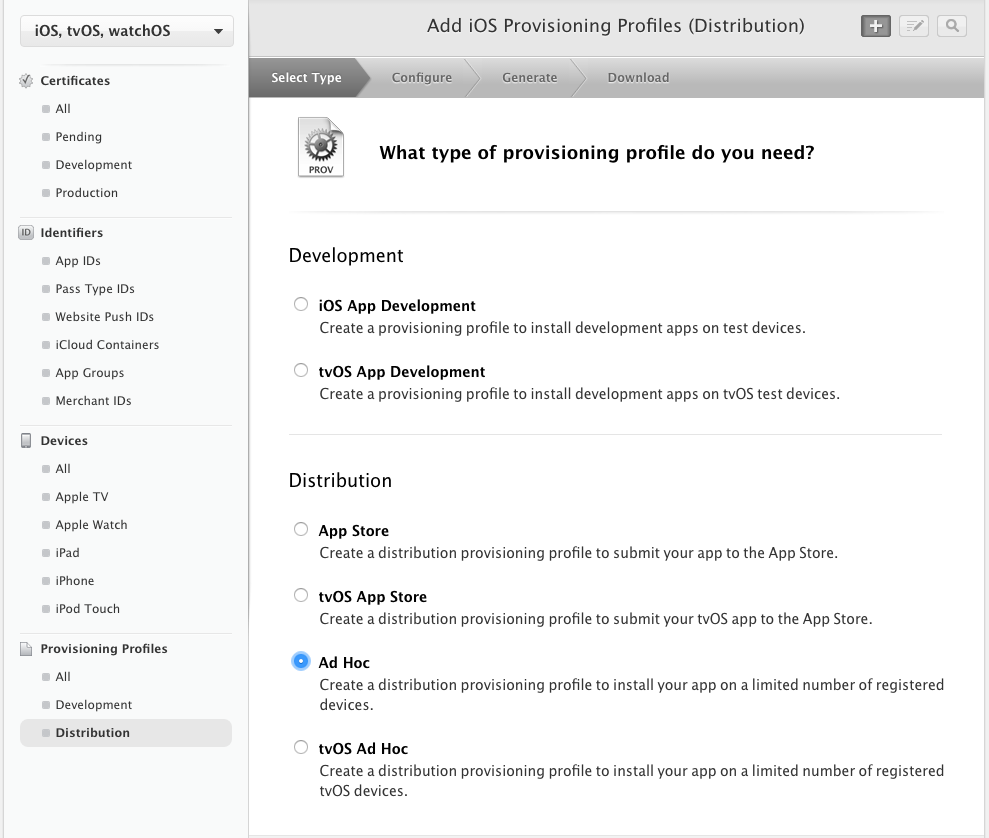
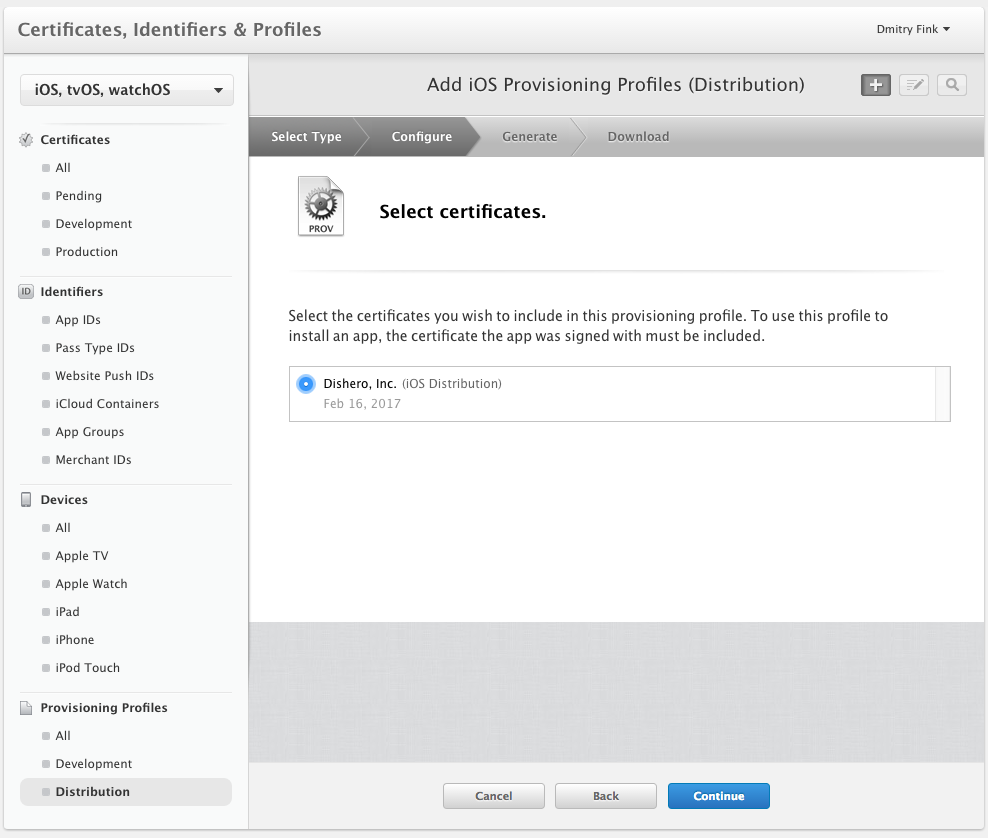
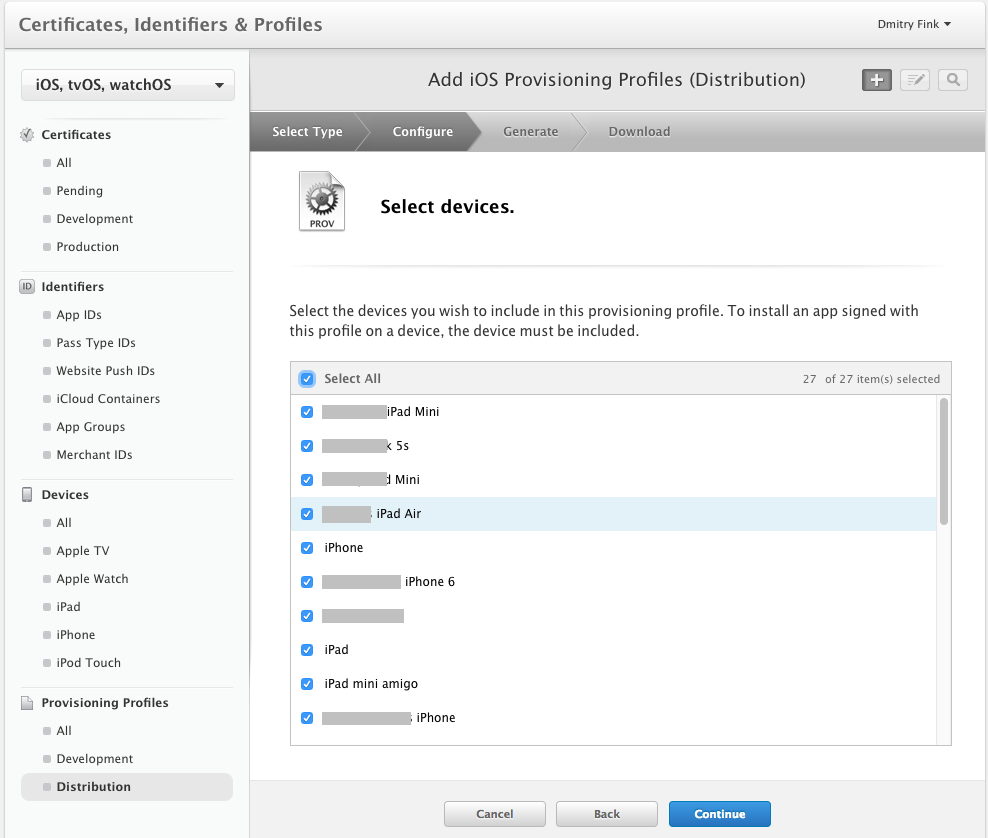
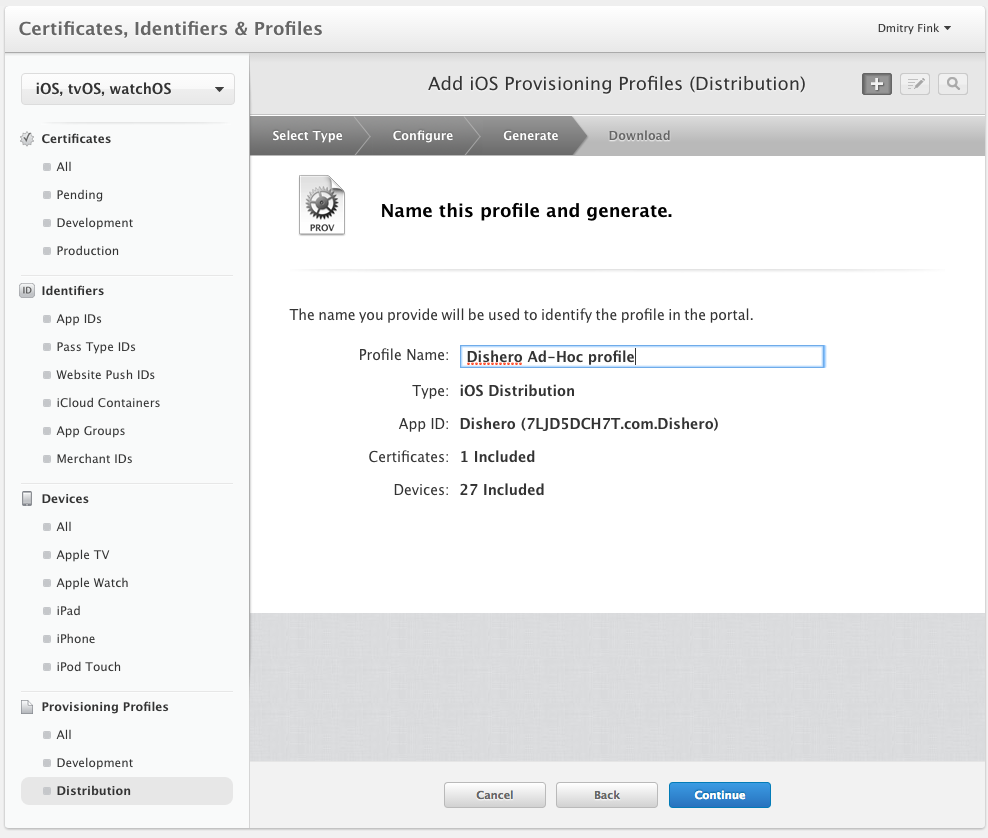
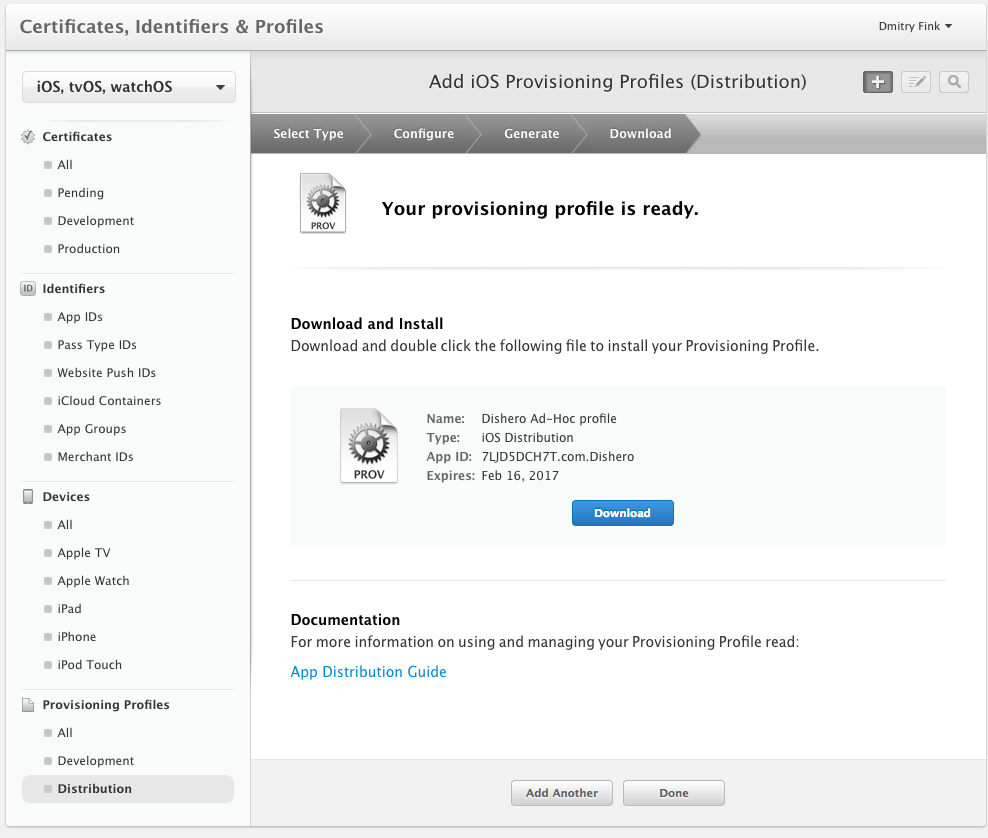
Follow the pictures below to create an Ad-Hoc provisioning profile, and add all the devices to it. Download it once ready and install in your local keychain by double-clicking on it.
Create a bucket on S3 and enable web hosting on it
You will also need a dedicated bucket on S3 for this. Make sure you enable Web Hosting on your bucket as shown in the picture below. Bonus: If you want to have your download page to be at a nice URL (we are using download.dishero.com for this example), you have to do a few tricks:
Name your bucket accordingly - download.dishero.com
In your DNS, configure a CNAME record download.dishero.com to point to download.dishero.com.s3.amazonaws.com.
Install S3cmd
We will need s3cmd to upload the files to S3 and set the right permissions.
<divclass="link"><ahref="itms-services://?action=download-manifest;url=${SECURE_TARGET}/${PROJECT}-${VERSION}-${BUILD}.plist">Tap to install!</a></div>
<p><strong>Link didn't work?</strong><br />Make sure you're visiting this page on your device, not your computer.</p>
</body>
</html>
INDEX_DELIM
echo "Uploading ${PROJECT}-${VERSION}-${BUILD}.ipa to s3://${TARGET}"
s3cmd put -P $FILE s3://${TARGET}/${PROJECT}-${VERSION}-${BUILD}.ipa
echo "Uploading ${PROJECT}-${VERSION}-${BUILD}.plist to s3://${TARGET}"
s3cmd put -P ${PROJECT}-${VERSION}-${BUILD}.plist s3://${TARGET}/${PROJECT}-${VERSION}-${BUILD}.plist
echo "Uploading index.html to s3://${TARGET}"
s3cmd put -P index.html s3://${TARGET}/
Executing the script requires only a few parameters: an IPA file, a bucket path, a version and a build
I feel stupid asking it, but where can I learn that sacral secret knowledge of typing hebrew text mixed with english, numbers and punctuation using modern editors and operating systems? Oh, and after typing, being able to copy-paste it to another app/window while preserving the right order of elements in a sentence. I can’t remember the last time I did that, I think the most popular text editor in Israel was called Einstein back then and copy-paste hasn’t been discovered by humanity yet, in any case I can’t seem to be able to do it now, no matter what I try. All I need is to type two short sentences.
We are running most of our backend code at Dishero on Amazon Elastic Beanstalk and it has been great so far. With Elastic Beanstalk we don’t need to worry about provisoning new instances and auto-scaling, in most cases it just allows us to upload our app and ELB takes care of the rest, however in some rare cases when we actually want to tinker with the internals and do some changes to the actual container it appears to be non-trivial and sometimes takes time to figure out.
Typical ELB setup
In a typical auto-scaled ELB setup, we have one elastic load balancer and multiple instances that execute our code. The setup is as follows:
Elastic Load Balancer is the one that is terminating the SSL connection, traffic to our instances is pure HTTP over port 80. You can find out more about setting up SSL certificates on Elastic Beanstalk here.
The instances are configured to forward all traffic from port 80 to 8080 using iptables.
Each instance has an NGINX running, which is listening on port 80880 and forwarding the traffic to our actual Node applicaiton.
The problem
We want to configure nginx to redirect all non-https traffic to https, and while we are at it to redirect all non-www traffic to www (i.e always push users to https://www.example.com/…).
It would be nice also to serve these as one redirect, taking a naive approach and writing two different rules (one for www and one for https) might result in two sequential redirects.
Since we are running the same configuration on multiple configurations which have different base URLs, we do not want to hardcode the actual URLs in the actual rulesm but rather keep them generic.
The solution
After several unsuccessfull iterations we arrived at the following set of rules:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
set$fixedWWW'';
set$needRedir0;
# nginx does not allow nested if statements
# check and decide on adding www prefix
if ($host !~* ^www(.*)) {
set$fixedWWW'www.';
set$needRedir1;
}
# what about that https? the traffic is all http right now
# but elastic load balancer tells us about the original scheme
# using $http_x_forwarded_proto variable
if ($http_x_forwarded_proto != 'https') {
set$needRedir1;
}
# ok, so whats the verdict, do we need to redirect?
if ($needRedir = 1) {
rewrite ^(.*)https://$fixedWWW$host$1redirect;
}
So the question is where should we put it?
The file that configures nginx to proxy traffic from 8080 to the application in the Elastic Beanstalk environment is located at /etc/nginx/conf.d/00_elastic_beanstalk_proxy.conf
Obviously, SSH’ing to all the instances, modifying the file and restarting nginx manually is of no use, it will get overwritten next time the app is deployed and newly deployed instances won’t have the changes either. Luckily for us Beanstalk allows us to customize the EC2 environment it provisions using configuration files, that system is pretty flexible and allows not only to install yum packages, write and overwrite files in the system, but to run commands and shell scripts during app deployments as well.
We may be tempted to use the config files to overwrite the 00_elastic_beanstalk_proxy.conf file in /etc/nginx/conf.d directly, and then wonder where are our changes and why they are nowhere to be seen in the system. Actually it might work well if all we want is add new nginx configuration files, but the issue is with existing nginx files, during the deployment process, the customization stage happens before nginx default files are being installed into their by the Elastic Beanstalk system, so even if we set up our copy of 00_elastic_beanstalk_proxy.conf, moments later it will still be overwritten with the default one. We need to overwrite that default one instead, and the source location of these is /tmp/deployment/config/, the one we are mostly interested in is suprisingly named #etc#nginx#conf.d#00_elastic_beanstalk_proxy.conf
So eventually, after all the trial and error, the solution appears to be quite simple, the one thing that needs to be added to our project is the following nginx.config file inside our .ebextensions folder:
Spent the evening setting up a new blog engine as I couldn’t revive the old one. This whole Ruby/Gem/Bundle mess is beyond me, it just never works. So this blog is now running on hexo. I am sure that won’t make me write more, but its Node.JS/NPM based, so at least I will be able to set it up again on a new machine if I suddenly do decide to.
What was it I wanted to blog about? I really can’t remember.